Certainly you can use the answer to generate the expected answer. We have an option in our standard Python3 question type for this. We use the given test case expected value if it's nonempty or we run the answer otherwise. It's good to have at least one
case where you manually provide the expected field, (a) to check your sample answer and (b) to provide a "for example" table.
It sounds like you're doing the right sort of thing, so I'm not sure what's not working. You need to use either a per-test-case template grader or combinator template grader. The latter is strongly recommended for production use because:
- It's much more efficient (involving just a single Jobe run for all tests if "Allow multiple stdins" is checked, rather than one run for each test case) and
- It's much more flexible, allowing any form of feedback.
However, a per-test-case template grader is much easier so I recommend that for a first step.
Here's the template for an Octave question type that uses a per-test-case template and fills in the expected output from the answer if none is given. The program to be tested, which is assumed to be a script rather than a function, consists of "clear;",
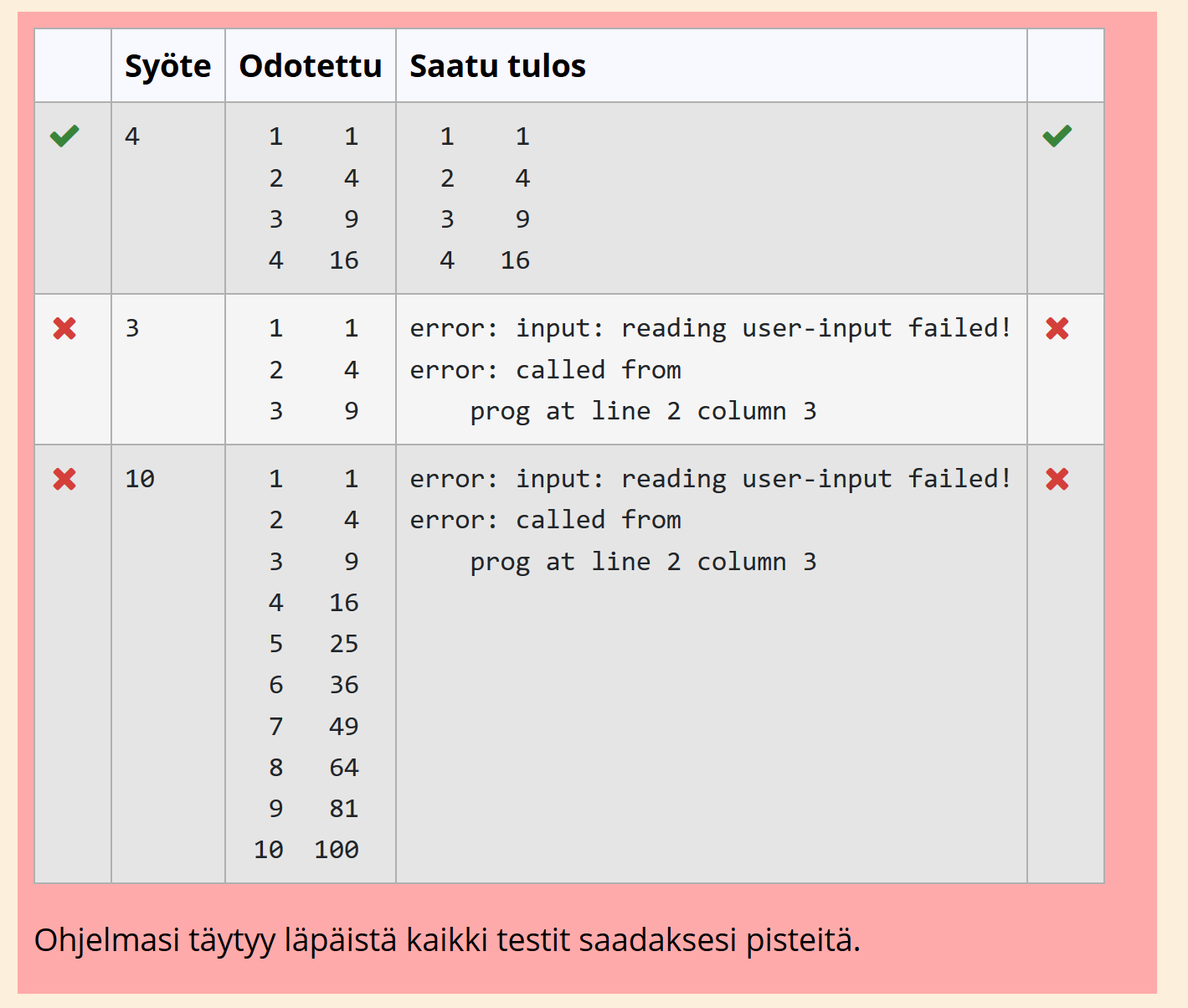
the student's answer, the test case and the 'extra' field in the test. This question type has had negligible testing - I wrote it only as a proof of concept. It requires a reasonably modern Python (at least 3.6).
""" A largely untested proof of concept question type to show how an
the test case expected field can be generated by running the sample answer.
This is a per-test-case template grader Q - inefficient compared to a combinator
template grader but easier to write.
"""
import subprocess, sys, json
def run_code(code, stdin=None):
"""Runs the given Octave code as a standalone program. The return value is
a tuple (output, stderr) where output is the standard output from the
program and stderr is the error output (and/or a message indicating what
error return code was received)."""
with open('prog.m', 'w', encoding='utf8') as source:
source.write(code)
failed = False
flags = '--silent --no-gui --no-history --no-window-system --norc'
command = 'octave {} prog.m'.format(flags).split()
output = ''
stderr = ''
try:
result = subprocess.run(
command,
capture_output=True,
input=stdin,
timeout=4, # Should be less than the Jobe timeout
text=True
)
except subprocess.TimeoutExpired:
stdout = ''
stderr = 'Timeout expired'
else:
stdout = result.stdout
stderr = result.stderr
if result.returncode < 0:
stderr += f"\nTask failed with signal {-result.returncode}"
return (stdout, stderr)
# Run job
def do_testing():
"""Run the current test case. If the expected output is empty, run the
sample answer code first.
"""
error = ''
test_expected = """{{ TEST.expected | e('py') }}""".rstrip()
if test_expected == '':
answer = """{{ QUESTION.answer | e('py') }}"""
stdin = """{{ TEST.stdin | e('py') }}"""
expected, error = run_code(answer, stdin)
if error:
outcome = {'expected': '', 'got': f"Error in question: {error}", "fraction": 0}
else:
test_expected = expected
if not error:
student_answer = """{{ STUDENT_ANSWER | e('py') }}"""
test_code = """{{ TEST.testcode | e('py') }}"""
extra = """{{ TEST.extra | e('py') }}"""
code_to_run = f'clear;\n{student_answer}\n{extra}\n'
output, error = run_code(code_to_run)
if error:
if output:
output += '\n' + error
else:
output = error
fraction = 1 if output.rstrip() == test_expected.rstrip() else 0
outcome = {'expected': test_expected, 'got': output, 'fraction': fraction}
print(json.dumps(outcome))
do_testing()
I attach an export of the question type and the one and only test question I've tried with it.