Thanks for the detailed report.
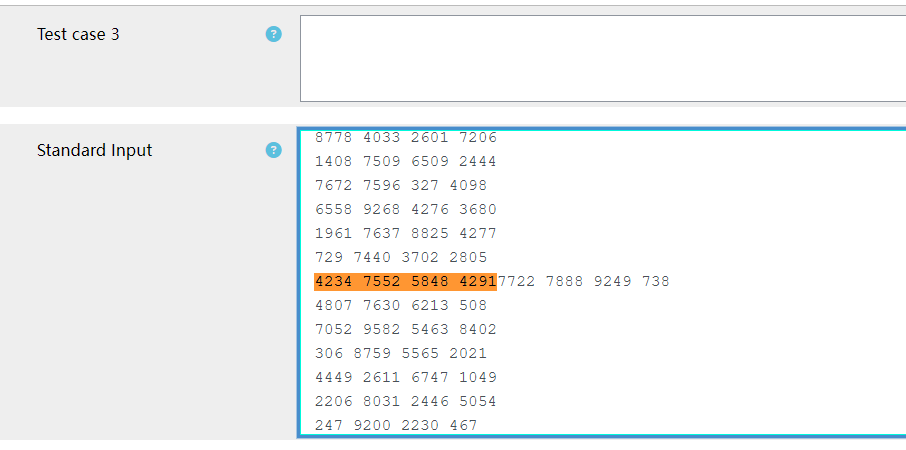
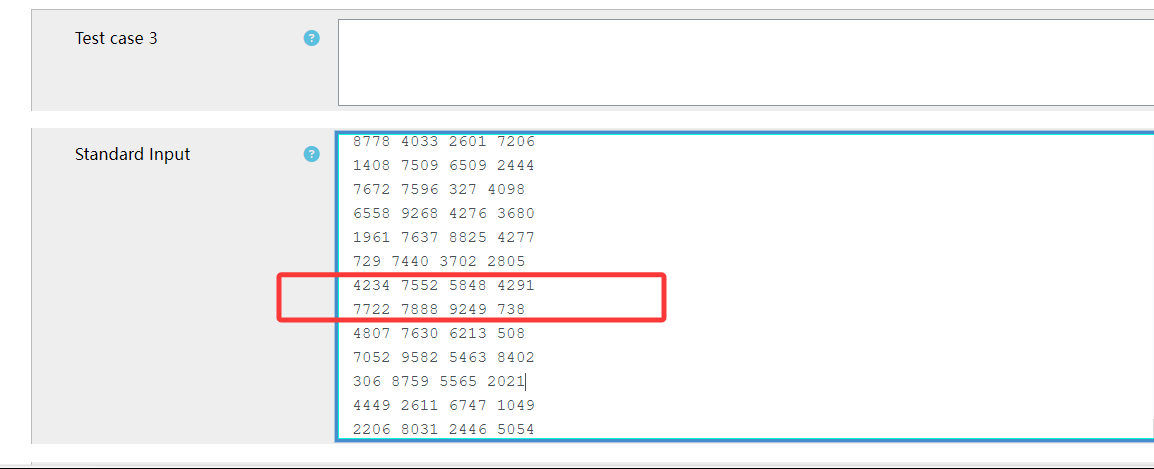
I can reproduce the issue, but can't explain it. I've put a breakpoint in the CodeRunner xml import function and it appears that those two lines of input data have already been run together in the parsed XML object that is passed into my function.
I've inspected the XML file in detail, put it through a validator and looked for any weirdness. Deleting all the Chinese text and replacing it with 8-bit UTF-8 characters just seems to move the bug further forward. The error occurs around character 190k - 210k even as I delete earlier testcases.
My only theory at this point is that there's a bug in the Moodle XML parser when handling large XML files, but that seems rather improbable. I have imported XML files way larger than this - up to a hundred megabytes or more - although they were questions with large support files rather than very long <text> elements, as are used for the <stdin> field.
So I'm sorry, I don't have an explanation for this, though it does seem to be a bug. I do have one additional question that may be relevant, however - how were the xml files generated? Presumably not from a Moodle export?
In an earlier posting you talked about the difficulty of using large datafiles in Moodle. But these datasets aren't particularly large. I have a large archive of programming contest problems that often have much larger datasets of 10s or even 100s of megabytes (though the latter need special settings). Do you wish to report in more detail on the difficulty you were having with datafiles of, say, a few hundred kilobytes?