Hello,
I have been exploring the possibilities of cr in implementing an HTML-question-type which has been successful and is exciting.
However, I need some direction on how to implement the regular expression grader for the new question-type.
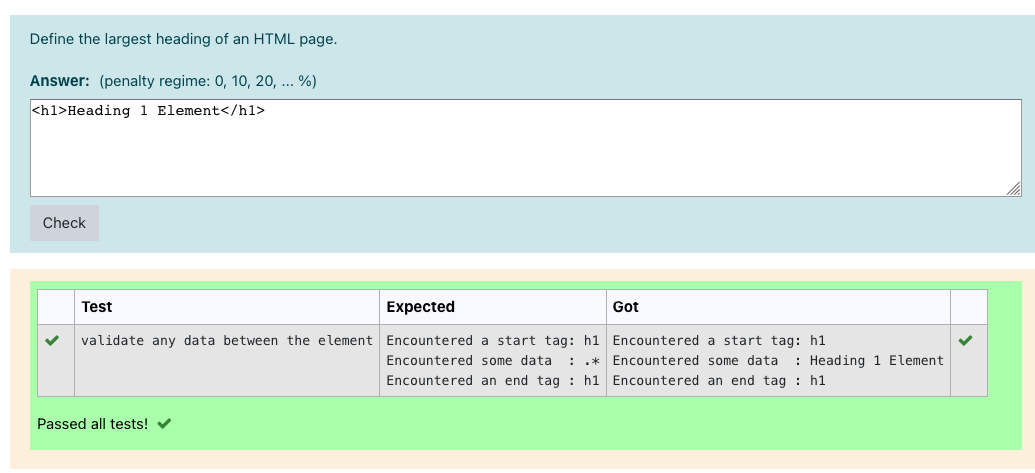
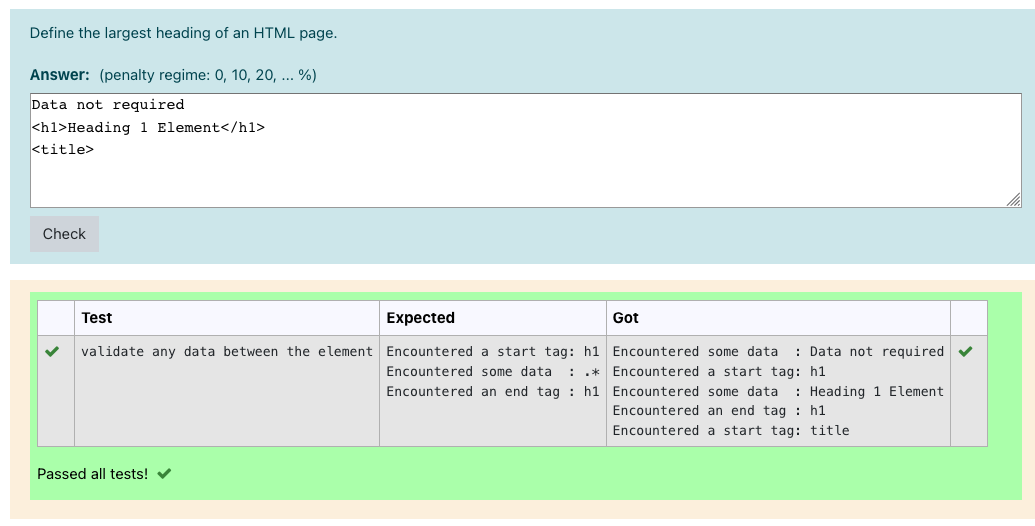
Here's a scenario: I am expecting the opening and closing tag with some data in the answer But I want to provide the flexibility of expecting any data in between the opening and ending tag. i.e. <h1>{any data}</h1>. I am using the Python HTML Parser. Hence when any code is provided as the answer to a question, it detects the tags sequentially. So I want to write a regular expression that would accept any word character.
I am not sure where exactly to write the regular expression whether in the Expected column of the test case when defining the question-type or in the test case for each question that uses the newly defined question-type.
I have already selected the Regular Expression as the Grading option when I was creating the Question-type I'm using for this question. I am currently trying to write the regex in the Expected column of a test case of this question but it isn't working.
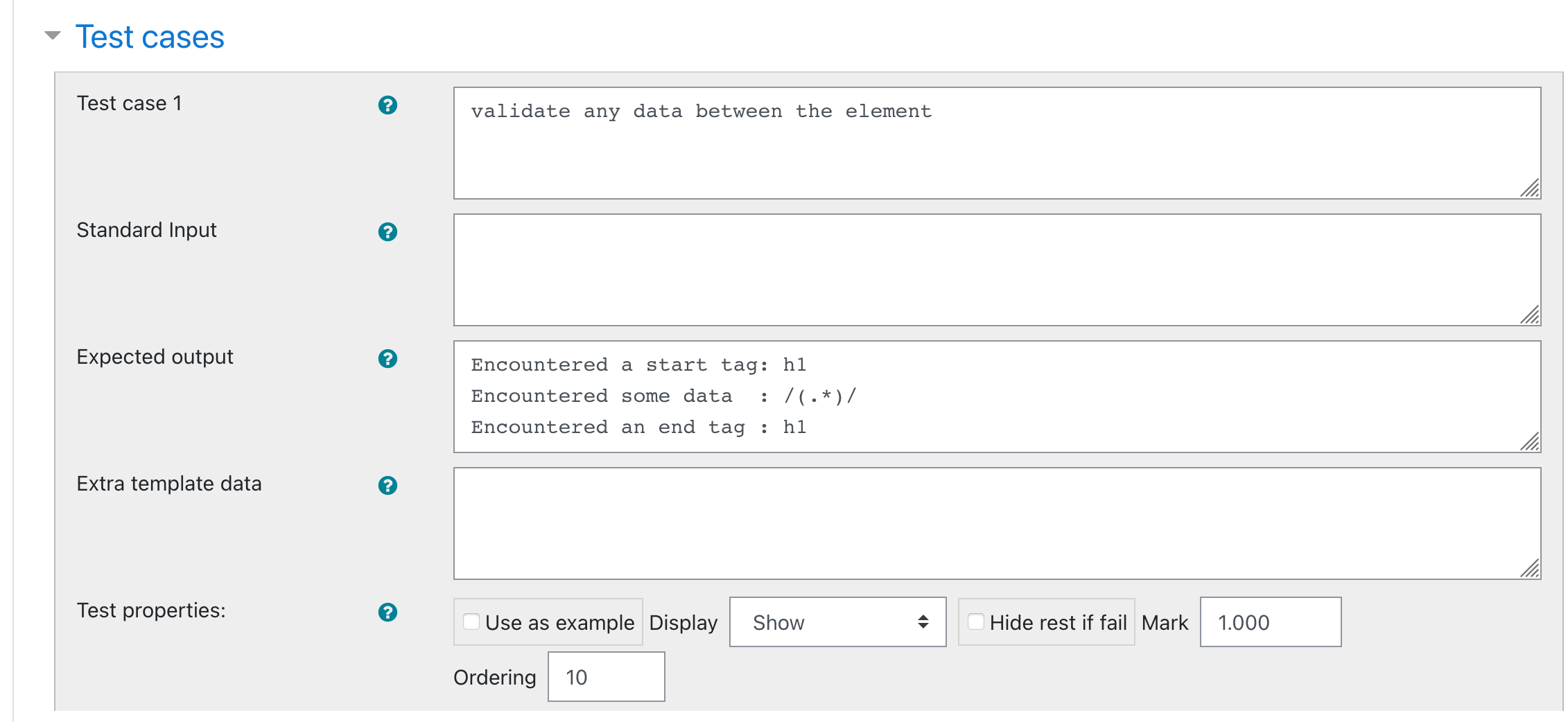
This is the results:
 But I want to accept any word character for the Encountered some data row using regex, how do I go about it?
But I want to accept any word character for the Encountered some data row using regex, how do I go about it?
Thanks in advance.