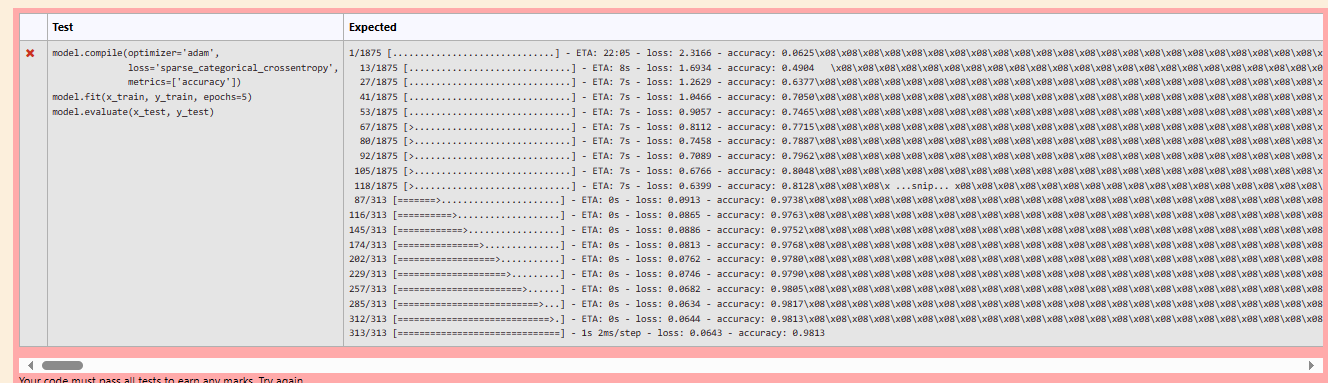
In this question I ask the students to attach a .h5 file of their saved neural network that they train on the Iris dataset. This is what the students see:
Upload your code for
the trained feed-forward neural network model on the Iris dataset,
scoring >90% accuracy on the validation set.
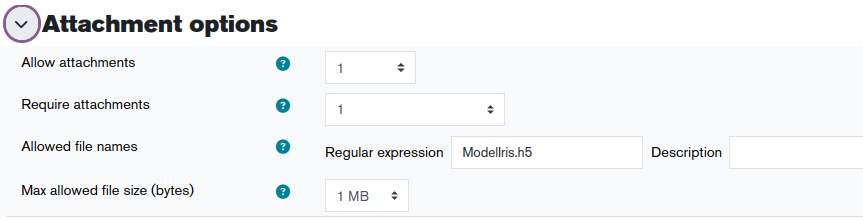
Use the "Attachment" feature below. Your file must be called "ModelIris.h5" and be under 1MB in size.
And here are the attachment options I offer the students:
Then there are 3 unit tests run by coderunner. (These unit tests look for exact string matches; but it's also possible to make it mark by regular expression, and just look for a specific keyword, e.g. "success".)
Test 1. Print the keras_model.summary():
import tensorflow as tf
print("TensorFlow version", tf.__version__) # This is a useful check to ensure the Jobe tensorflow package has not been upgraded since you wrote this test script.
keras_model=tf.keras.models.load_model('ModelIris.h5') # This is the filename of the saved neural network I ask them to attach
keras_model._name="my_neural_network"
c=0
for layer in keras_model.layers:
c+=1
layer._name = "layer"+str(c) # Ensures the layers are named consistently; so we can get an exact string match on the model summary
keras_model.summary()
Test 2. Print out the activation functions from each layer.import tensorflow as tf
import os, contextlib
with open(os.devnull, 'w') as devnull:
with contextlib.redirect_stdout(devnull):
keras_model=tf.keras.models.load_model('ModelIris.h5')
keras_model._name="my_neural_network"
c=0
for layer in keras_model.layers:
c+=1
if isinstance(layer, tf.keras.layers.Conv2D) or isinstance(layer, tf.keras.layers.Dense):
print("Layer",c,"Activation Function",layer.activation.__name__)
Test 3. Check their saved neural network has learned the validation set sufficiently well.
import pandas as pd
import tensorflow as tf
inputs_val=pd.read_csv('iris_test.csv',usecols = [0,1,2,3],skiprows = None,header=None).values # Note here I've added the file iris_test.csv as one of the "support files" in the coderunner question definition.
labels_val = pd.read_csv('iris_test.csv',usecols = [4],skiprows = None ,header=None).values.reshape(-1)
keras_model=tf.keras.models.load_model('ModelIris.h5')
predictions = tf.math.argmax(keras_model(inputs_val),axis=1)
accuracy=tf.reduce_mean(tf.cast(tf.equal(predictions,labels_val),tf.float32)).numpy()
print("Validation Accuracy Exceeds 90%?",accuracy>0.9)
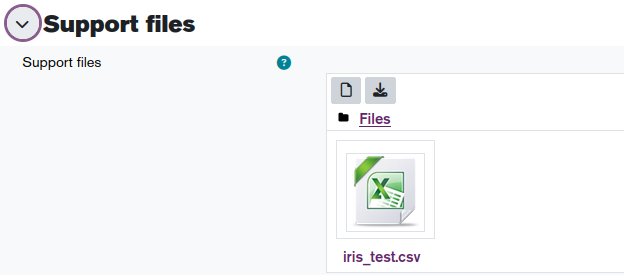
Here is how I uploaded my support file:
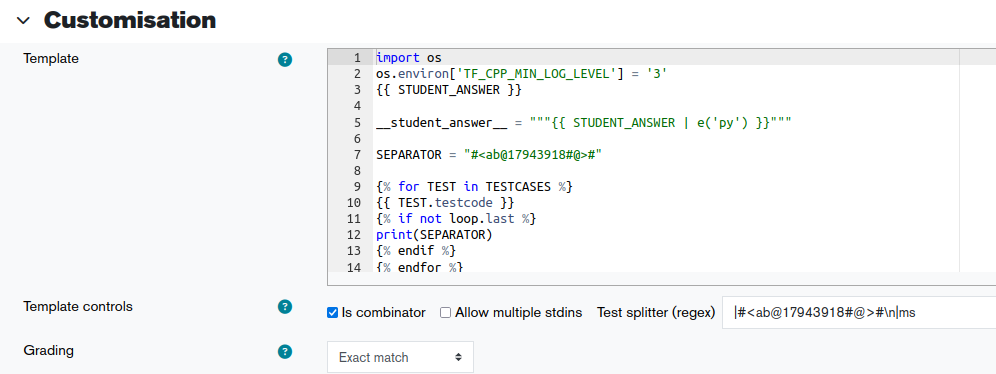
To make tensorflow not display lots of warning messages, which would break the exact-string matching, we have these first 2 lines added to set TF_CPP_MIN_LOG_LEVEL...
I just have the "answer" and "answer-box preload" fields empty.
For the "expected outputs", I just run it once on my own answer (a single saved .h5 file) and capture the output.
This works well, but every year there is a new tensorflow version and I have to re-build the expected string outputs (as tensorflow seems to tweak the exact layout of model.summary() each new version!)